Inhaltsverzeichnis
Sie kommen lautlos, ungebeten – und hinterlassen Chaos. Spam-Bots sind der Albtraum vieler Webseitenbetreiber: Sie fressen Serverressourcen, fluten Kontaktformulare, legen Fake-Accounts an und manipulieren SEO-Daten. Während man sich über echte Nutzer auf seiner Seite freut, sind es oft nur automatisierte Programme, die sich an unseren Inhalten bedienen oder unsere Shops verlangsamen. Aber es gibt Mittel und Wege, ihnen das Handwerk zu legen 😎
🧰 Maßnahmen gegen nervige Bots
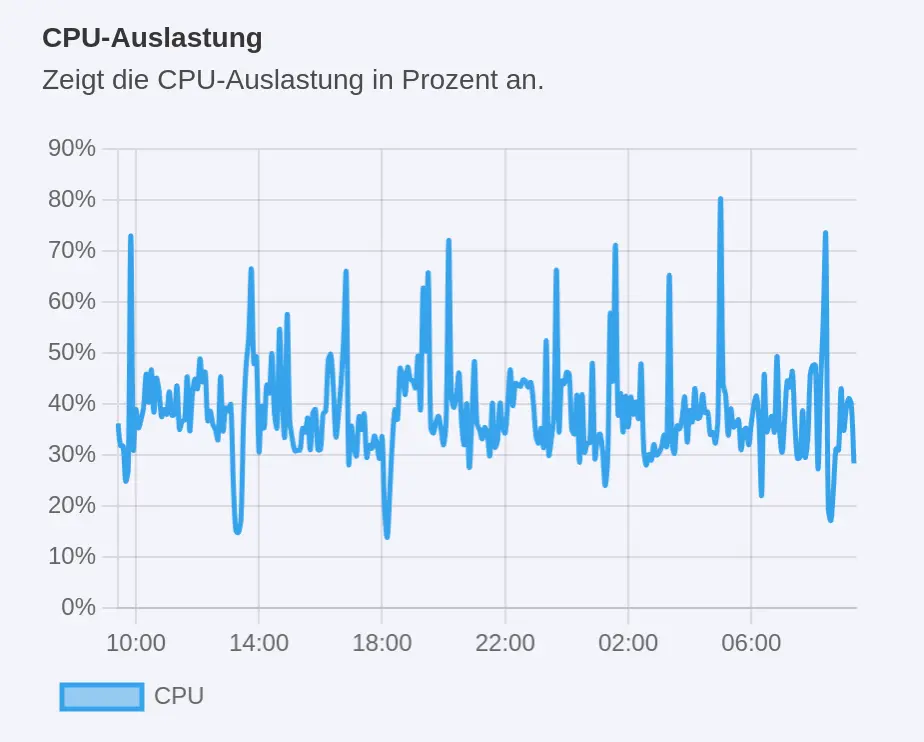
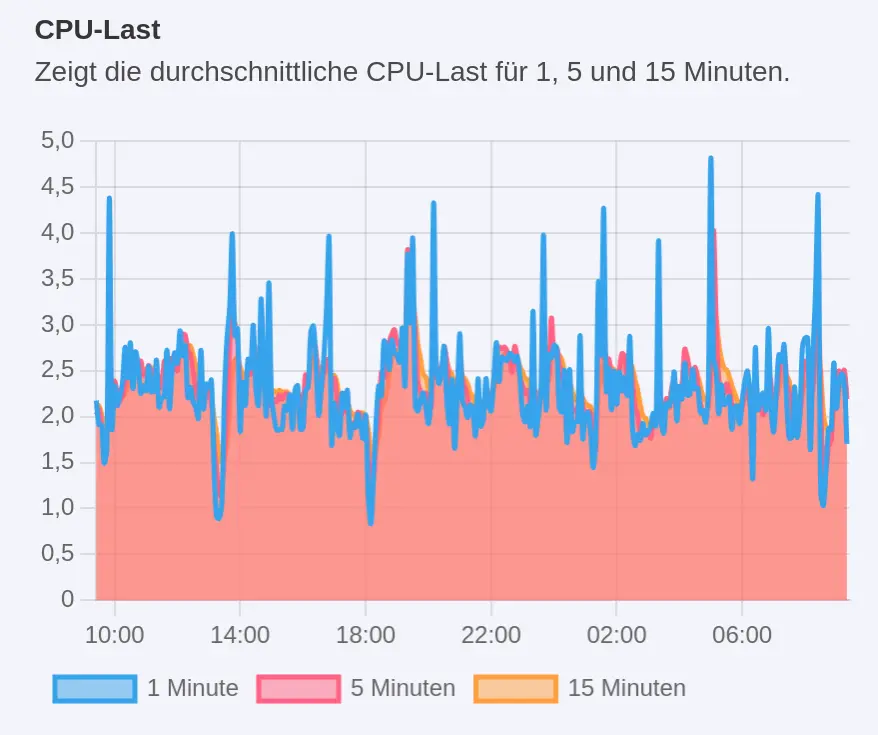
Immer wieder werden mir Empfehlungen des beliebten Gambio Hosting Anbieters Estugo weitergeleitet. Aggressive Bots auszusperren ist nicht das Allheilmittel für eine kürzere Gambio Ladezeit. Aber es ist eine Stellschraube, an der man unbedingt drehen sollte.
Im Kampf gegen Spam-Bots stehen uns laut Blog-Beitrag bei Estugo verschiedene effektive Maßnahmen zur Verfügung, die sich je nach Bedarf kombinieren lassen:
1. Sicherheits-Tools und Firewalls 🔧
Cloudflare bietet umfassenden Schutz vor DDoS-Angriffen und blockiert Spam-Bots durch Traffic-Analyse. Wordfence (für WordPress) integriert eine Firewall und erkennt sowie blockiert Bots basierend auf IP-Adressen und Verhalten. Sucuri Security schützt vor Malware, Spam und Bots. Diese Tools arbeiten in Echtzeit und aktualisieren sich kontinuierlich, um neue Bedrohungen schnell zu erkennen.
2. Einsatz der robots.txt 📄
Die robots.txt-Datei steuert, welche Bereiche deiner Website von Suchmaschinen-Crawlern indexiert werden dürfen. Sie kann auch verwendet werden, um bösartige Bots von bestimmten Bereichen fernzuhalten. Allerdings ignorieren viele schädliche Bots diese Regeln, weshalb die robots.txt eher als ergänzende Maßnahme dient.
3. IP-Adressen via .htaccess sperren 🔒
Durch Anpassungen in der .htaccess-Datei können wir gezielt IP-Adressen oder ganze IP-Bereiche blockieren, die wiederholt unerwünschten Traffic verursachen. Diese Methode ist effektiv, erfordert jedoch regelmäßige Updates und Pflege, um neue Bedrohungen abzudecken.
4. Kombination der Maßnahmen 🧠
Die wohl effektivste Strategie besteht in der Kombination der genannten Maßnahmen:
- Echtzeit-Tools wie Cloudflare oder Wordfence bieten schnellen und umfassenden Schutz.
- robots.txt dient als ergänzende Kontrolle, um gutartige Bots zu lenken.
- .htaccess-Anpassungen ermöglichen die gezielte Blockierung bekannter Spam-Bots.
Durch diese kombinierte Herangehensweise können wir unsere Website optimal vor Spam-Bots schützen
🚫 Sperren statt bitten
Ich persönlich halte nichts davon, mich auf die „Höflichkeit“ von Bots zu verlassen. Klar, die robots.txt ist eine nette Geste – sozusagen ein digitales „Bitte nicht stören“. Aber die Realität ist: Die meisten Spam-Bots ignorieren solche Bitten einfach. Sie lesen die Datei gar nicht erst oder tun so, als gäbe es sie nicht.
Deshalb mein klarer Favorit: direktes Blockieren via .htaccess und RewriteCond-Regeln. Das ist wie eine Tür mit Schloss – nicht nur ein Schild, das freundlich um Ruhe bittet. Wer keinen legitimen Zweck verfolgt, fliegt raus – kompromisslos und automatisiert.
⚠️ Nicht blind übernehmen
Bevor wir zur digitalen Keule greifen und die RewriteCond-Liste aus diesem Beitrag 1:1 in unsere .htaccess-Datei kopieren: Wir sollten uns unbedingt bewusst machen, was wir da eigentlich tun.
Denn so wirkungsvoll das Blockieren von Bots auch ist – es kann uns schnell selbst schaden, wenn wir ohne Plan vorgehen.
Ein paar Beispiele aus der Praxis:
- SEO-Tools wie SISTRIX, Seobility, Searchmetrics oder SEMrush:
Diese Dienste arbeiten mit eigenen Crawlern, um unsere Website zu analysieren. Sperren wir sie aus, bekommen wir keine oder nur sehr eingeschränkte Analysen – Sichtbarkeitsindizes, Rankings oder technische SEO-Audits werden dann unvollständig oder gar nicht dargestellt. - YandexBot (Russland), Baiduspider (China), NaverBot (Südkorea):
Wenn wir in einem dieser Länder nennenswerten Traffic oder Umsatz generieren, sollten wir diese Bots nicht blockieren – dort sind sie genauso wichtig wie bei uns Google. - Googlebot, Bingbot & Co.:
Wenn wir in Suchmaschinen gefunden werden wollen, dürfen wir diese Bots keinesfalls aussperren. Auch spezialisierte Varianten wie Googlebot-Image, Google-AdsBot, BingPreview oder Applebot (z. B. für Siri und Spotlight) gehören auf die Positivliste, damit wir Googlebots Abenteuer in den Gambio-Kategorien keine Steine in den Weg legen. - Bots für Link-Vorschauen in sozialen Netzwerken:

Facebook-Linkvorschau Wenn jemand unsere Seite auf Social Media teilt, rufen bestimmte Bots die Seite auf, um eine Vorschau zu generieren – mit Bild, Titel und Beschreibung. Sperren wir sie, erscheinen geteilte Links leer oder unattraktiv. Wichtige Beispiele:
facebookexternalhit→ Facebook LinkvorschauTwitterbot→ Twitter/X VorschauLinkedInBot→ LinkedIn-Post-VorschauSlackbot→ Vorschauen in SlackTelegramBot→ Vorschau in Telegram-ChatsWhatsApp→ Vorschau bei geteilten Links in WhatsApp

Fazit:
Wenn wir Crawler blockieren, sollten wir immer genau wissen, welche Auswirkungen das hat – auf Analyse-Tools, Suchmaschinen-Rankings und Social Media. Besser gezielt blockieren als vorschnell alles aussperren.
🛡️ Liste zur gezielten Bot-Blockierung
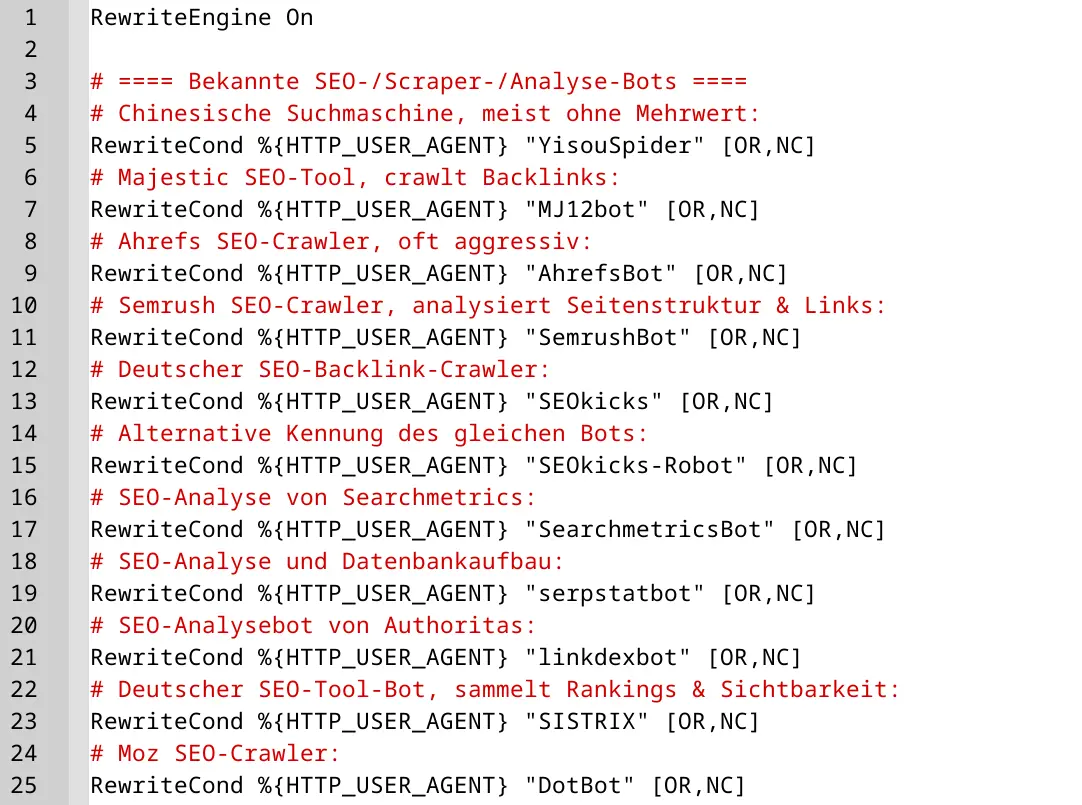
Wenn wir uns sicher sind, dass bestimmte Bots für unsere Website keinen Nutzen bringen, können wir sie gezielt aussperren. Kommen wir also endlich zum Punkt:
RewriteEngine On
# ==== Bekannte SEO-/Scraper-/Analyse-Bots ====
# Chinesische Suchmaschine, meist ohne Mehrwert:
RewriteCond %{HTTP_USER_AGENT} "YisouSpider" [OR,NC]
# Majestic SEO-Tool, crawlt Backlinks:
RewriteCond %{HTTP_USER_AGENT} "MJ12bot" [OR,NC]
# Ahrefs SEO-Crawler, oft aggressiv:
RewriteCond %{HTTP_USER_AGENT} "AhrefsBot" [OR,NC]
# Semrush SEO-Crawler, analysiert Seitenstruktur & Links:
RewriteCond %{HTTP_USER_AGENT} "SemrushBot" [OR,NC]
# Deutscher SEO-Backlink-Crawler:
RewriteCond %{HTTP_USER_AGENT} "SEOkicks" [OR,NC]
# Alternative Kennung des gleichen Bots:
RewriteCond %{HTTP_USER_AGENT} "SEOkicks-Robot" [OR,NC]
# SEO-Analyse von Searchmetrics:
RewriteCond %{HTTP_USER_AGENT} "SearchmetricsBot" [OR,NC]
# SEO-Analyse und Datenbankaufbau:
RewriteCond %{HTTP_USER_AGENT} "serpstatbot" [OR,NC]
# SEO-Analysebot von Authoritas:
RewriteCond %{HTTP_USER_AGENT} "linkdexbot" [OR,NC]
# Deutscher SEO-Tool-Bot, sammelt Rankings & Sichtbarkeit:
RewriteCond %{HTTP_USER_AGENT} "SISTRIX" [OR,NC]
# Moz SEO-Crawler:
RewriteCond %{HTTP_USER_AGENT} "DotBot" [OR,NC]
# Alternative Schreibweise:
RewriteCond %{HTTP_USER_AGENT} "dotbot" [OR,NC]
# Webanalyse-Bot von Blex.io, indexiert umfassend:
RewriteCond %{HTTP_USER_AGENT} "BLEXBot" [OR,NC]
# AI-gesteuerter Chatbot, crawlt Inhalte für Interaktionen:
RewriteCond %{HTTP_USER_AGENT} "Brightbot" [OR,NC]
# Browser-basierter Crawler, sammelt Nutzungsdaten:
RewriteCond %{HTTP_USER_AGENT} "Cliqzbot" [OR,NC]
# Kontextbezogene Werbe-Crawler (Oracle):
RewriteCond %{HTTP_USER_AGENT} "GrapeshotCrawler" [OR,NC]
# B2B-Firmendaten-Sammler, kein Nutzen für Seitenbetreiber:
RewriteCond %{HTTP_USER_AGENT} "ZoominfoBot" [OR,NC]
# SEO-Linkanalyse-Tool:
RewriteCond %{HTTP_USER_AGENT} "OpenLinkProfiler" [OR,NC]
# Russischer SEO-Crawler:
RewriteCond %{HTTP_USER_AGENT} "MegaIndex.ru" [OR,NC]
# Crawler mit Fokus auf Sicherheits- oder Netzwerkanalyse:
RewriteCond %{HTTP_USER_AGENT} "ltx71" [OR,NC]
# Firmendaten-Sammler für Marktanalysen:
RewriteCond %{HTTP_USER_AGENT} "InoopaBot" [OR,NC]
# SEO-Analysebot:
RewriteCond %{HTTP_USER_AGENT} "AlphaSeoBot" [OR,NC]
# SEO-Datenanbieter, crawlt intensiv:
RewriteCond %{HTTP_USER_AGENT} "DataForSeoBot" [OR,NC]
# Forschungscrawler, extrem skalierbar – hoher Traffic:
RewriteCond %{HTTP_USER_AGENT} "BUbiNG" [OR,NC]
# SEO-Crawler von babbar.tech:
RewriteCond %{HTTP_USER_AGENT} "Barkrowler" [OR,NC]
# Monitor für Online-Erwähnungen:
RewriteCond %{HTTP_USER_AGENT} "AwarioRssBot" [OR,NC]
# Intelligenter Bot für Social Listening:
RewriteCond %{HTTP_USER_AGENT} "AwarioSmartBot" [OR,NC]
# Sehr aggressiver Bot mit wechselnden IPs, häufig blockiert:
RewriteCond %{HTTP_USER_AGENT} "MauiBot" [OR,NC]
# Früherer Bot der Suchmaschine Exalead – mittlerweile ohne Nutzen:
RewriteCond %{HTTP_USER_AGENT} "Exabot" [OR,NC]
# Crawlt Webseiten für maschinelles Lernen (Sprachmodelle):
RewriteCond %{HTTP_USER_AGENT} "Paracrawl" [OR,NC]
# ==== Allgemeine Scraping- und Entwickler-Tools ====
# Offline-Website-Kopierer, belastet Server stark:
RewriteCond %{HTTP_USER_AGENT} "HTTrack" [OR,NC]
# Kommandozeilentool zum Kopieren ganzer Seiten:
RewriteCond %{HTTP_USER_AGENT} "wget" [OR,NC]
# CLI-Tool, häufig für automatisiertes Scraping genutzt:
RewriteCond %{HTTP_USER_AGENT} "curl" [OR,NC]
# Python-Basisskripte zum Crawling:
RewriteCond %{HTTP_USER_AGENT} "Python-urllib" [OR,NC]
# Python-Webscraping-Framework:
RewriteCond %{HTTP_USER_AGENT} "Scrapy" [OR,NC]
# Java-Webcrawler, oft für aggressive Scraping-Tools verwendet:
RewriteCond %{HTTP_USER_AGENT} "crawler4j" [OR,NC]
# Webarchivierungs-Bot, wird z.B. vom Internet Archive verwendet:
RewriteCond %{HTTP_USER_AGENT} "heritrix" [OR,NC]
# Allgemeiner Java-basierter Crawler:
RewriteCond %{HTTP_USER_AGENT} "Java/" [OR,NC]
# RSS-Reader Feedly, kann hohe Last erzeugen:
RewriteCond %{HTTP_USER_AGENT} "feedly" [OR,NC]
# ==== Weitere Botdienste, Tracking, Analyse & Archivierung ====
# Ermittelt technische Details, z. B. Webserverdaten:
RewriteCond %{HTTP_USER_AGENT} "NetcraftSurveyAgent" [OR,NC]
# Wayback Machine – kann auf Wunsch blockiert werden:
RewriteCond %{HTTP_USER_AGENT} "archive.org_bot" [OR,NC]
# Ehemaliger MozBot, manchmal noch unterwegs:
RewriteCond %{HTTP_USER_AGENT} "rogerbot" [OR,NC]
# Medienanalyse-/Aggregatorbot:
RewriteCond %{HTTP_USER_AGENT} "trendictionbot" [OR,NC]
# Sicherheitsanalyse, erzeugt viel Traffic:
RewriteCond %{HTTP_USER_AGENT} "ScreenerBot" [OR,NC]
# ==== Lokale, Forschungs- oder wenig dokumentierte Bots ====
# Uni Mannheim – linguistische Korpus-Crawler:
RewriteCond %{HTTP_USER_AGENT} "um-IC" [OR,NC]
RewriteCond %{HTTP_USER_AGENT} "um-LN" [OR,NC]
# Crawlt Jobanzeigen:
RewriteCond %{HTTP_USER_AGENT} "iCjobs" [OR,NC]
# Mail.ru Bot – russischer Dienst:
RewriteCond %{HTTP_USER_AGENT} "MTRobot" [OR,NC]
# Deutscher Suchmaschinen-Bot:
RewriteCond %{HTTP_USER_AGENT} "SeekportBot" [OR,NC]
# Südkoreanischer Suchmaschinen-Crawler:
RewriteCond %{HTTP_USER_AGENT} "Daum" [OR,NC]
# ==== Weitere „höfliche“ Crawler, die oft nichts bringen ====
# Hält sich an Regeln, liefert aber selten echten Nutzen:
RewriteCond %{HTTP_USER_AGENT} "polite-crawler" [OR,NC]
# Desktop-Tool für SEO-Audits – bei Bedarf blockierbar:
RewriteCond %{HTTP_USER_AGENT} "Screaming Frog SEO Spider" [NC]
# Block-Regel
RewriteRule ^(.*) - [L,F]
Was machen wir nun mit dieser Liste? Zunächst Zeile für Zeile durchgehen 🙂 Nur, wenn wir ganz sicher sind, dass wir den jeweiligen Bot aussperren möchten, übernehmen wir die jeweilige RewriteCond. Das Ergebnis können wir dann in die .htaccess im Hauptverzeichnis ganz oben einfügen. Für noch mehr Performance und mit entsprechendem Zugriff können wir die Angaben auch direkt in die Webserverkonfiguration einfügen.
Mehr Performance, mehr Sicherheit – weniger Ärger:
Indem wir überflüssige und unerwünschte Bots gezielt aussperren, entlasten wir unseren Server, schützen sensible Bereiche vor automatisierten Zugriffen und behalten die Kontrolle über unsere Inhalte. Egal ob wir einen Gambio-Shop, eine WordPress-Seite, ein CMS wie Contao oder ein anderes System betreiben – am Ende profitieren wir alle von:
- schnelleren Ladezeiten
- weniger Serverlast
- saubereren Analyse-Daten
- und mehr Ruhe im Logfile
Mit der richtigen Konfiguration sorgen wir dafür, dass nur die Besucher auf unsere Seite kommen, die wir dort auch wirklich haben wollen – und die übrigen sich höflich verabschieden müssen 😎